Я уже разбирался несколько месяцев назад, как Claude Code стремится экономить токены во время работы. Но с тех пор тема экономии стала намного более актуальной — сначала у Anthropic вышли модели с новым токенизатором, который использовал на 30-35% больше токенов по сравнению с предыдущей версией, а потом наступил Fable, который их расходует еще более щедро и при этом отдельно лимитируется на дорогих подписках и вообще тарифицируется отдельно на остальных.
Даже если вы не такой уж тяжелый пользователь, тема экономии токенов может быть актуальна — как минимум, от количества обрабатываемых токенов прямо зависит время обработки и очень часто — качество результата.
Проблема актуальна не только для пользователей Claude Code — с начала лета GitHub Copilot перевел свои тарифы на токены, а самые мощные модели вообще увел с большими мультипликаторами в более дорогие подписки. Если добавить, что как раз к концу мая компании вдруг поняли, сколько они реально расходуют ресурсов — при непонятном результате, — и начали зажимать расходы, то понятно, почему тема экономии обогнала тему запуска всяких персональных агентов.
Честно говоря, до релиза Fable 5 у меня вопрос об экономии токенов вообще не стоял — мне не удавалось потратить недельные лимиты ни разу, как бы интенсивно я их не использовал. Правда, скажу честно — я не придумывал задачи, чтобы потратить лимиты, не запускал агентов в цикле на много часов — просто решал имеющиеся задачи. Fable лишь заставил более критически посмотреть на организацию работы и помог пересмотреть некоторые узкие места.
Помните относительно недавнюю историю про то, как у разработчиков PocketOS (в компании, которая занимается разработкой ПО для проката авто) Cursor с Opus 4.6 удалил продакшн-базу с бэкапами? Там на самом деле можно по большому количеству пунктов показать, что компания вместе с своим облачным провайдером сами себе выстрелили в ногу, но меня особенно впечатлила одна деталь — в промпте агента было написано дословно “NEVER FUCKING GUESS”.Объяснение агента после инцидентаПо заглавным буквам и матерной инструкции легко догадаться, что агент уже не раз вместо конкретных проверок пытался угадать факты и промахивался. А его хозяин постепенно раздражался.
Но вот какое дело — текстовые промпты, которыми чаще всего оперируют в управлении агентами, по сути не являются жесткими приказами, а больше похожи на просьбы. Это гораздо легче воспринять, если относиться к LLM не как к бинарному оператору “выполняет-не выполняет”, а как к сверхсложной системе, где ваши команды являются лишь сильным управляющим сигналом. Строго говоря, и компьютерные программы, которые некоторые приводят в качестве образца детерминированности, далеко ушли от по-настоящему детерминированного процесса, происходящего в транзисторе — иначе бы у нас не было понятия “багов”. Но LLM еще сложнее и поэтому я всегда советую относиться к агенту скорее как к сотруднику. Сотрудник-человек тоже недетерминирован и как бы громко и конкретно вы не давали ему указание, он может проигнорировать ваше “Never fucking do!” и сделать, как захочет.
Перестаньте упрашивать модель. Особенно когда вы уже видите, что она может проигнорировать просьбы. Фигурально выражаясь, вы знаете, что “сотрудник” способен на нежелательный поступок, но продолжаете держать на его столе большую красную кнопку, уничтожающую всё, и даже не ставите её на предохранитель.
Любое ALWAYS или NEVER в промптах агента — это кандидат на замену детерминированным инструментом. Большинство агентов позволяют настроить hooks, когда по определенным событиям в работе программная обвязка агента — не модель, а программа, через которую модель взаимодействует с остальной системой, — выполняет жестко прописанные команды. Вы хотите обезопасить систему, чтобы агент не перезапускал сам важные элементы системы?
Хотите, чтобы агент не смог удалить важные файлы? Аналогичный хук может запустить скрипт, который проверит, что файловая операция не относится к “защищенным” файлам, в противном случае заблокирует её.
Хотите дать агенту возможность осуществлять какие-то операции в живой системе, например, через API? Прежде всего, дайте ему в API права делать только то, что ему можно делать — в той самой истории про PocketOS оказалось, что токены в Railway имели только один вид прав, а именно максимальные, о чем не знали пользователи. Во-вторых, разработайте скилл-обертку вокруг API, где будут реализованы только нужные операции. В-третьих, не давайте агенту прав запускать что-либо, кроме этого скилла (там может быть скрипт), и запретите ему редактировать скилл — это можно реализовать либо хуком, упомянутым выше, либо разделением агентов, основной будет иметь инструкцию обязательно выполнять операцию через субагента, а у субагента прав редактировать скрипты не будет.
Аналогично можно транслировать в инструменты и инструкцию типа ALWAYS. Вы хотите, чтобы он всегда после правок скрипта проверял синтаксис? Включите LSP и хуком на операцию Edit/Write запускайте линтер. Результат работы линтера будет возвращаться сразу после редактирования и агент сразу будет видеть ошибку. Надо, чтобы он всегда помнил текущую дату? Поставьте хук на SessionStart и скриптом вписывайте в контекст “Сегодня ХХ июня 2026 года, твое обучение закончилось 5 месяцев назад, если вопрос касается версий, API и прочего, проверь поиском актуальную информацию, не полагайся на знания”.
И, конечно, еще раз повторю — пуская агента в живую систему, используйте способы ограничения доступа, придуманные для людей, то есть права пользователей, разрешения на операции, доступ только на чтение и надежные бэкапы (не на том же томе, что и рабочая система, как это было у PocketOS).
Вы, вероятно, сталкивались с тем, как LLM при генерации ответа меняют язык — например, вставляют английские слова в русский текст или, получив запрос на русском, отвечают на украинском. Это объясняется довольно просто — с одной стороны, для модели это всё информация и она не видит разницы между языками с точки зрения её передачи. Это тот же эффект, который наблюдается у людей, много говорящих на разных языках — от профессионального жаргона до анекдотичного “Вам cheese по-slice-ить или piece-ом положить?”. С другой стороны, когда вы задаете запрос, модель получает не только текст запроса, но много другого — системный промпт (на английском), ваши настройки, содержание документов, которые загружаете в чат и так далее. Неудивительно, что, получив на вход информацию на нескольких языках, модель отвечает на одном из них или даже на нескольких сразу.
Но это неудобно, когда вы хотите получить на выходе читаемый текст вне контекста. Например, у меня есть несколько задач, когда агент читает много разных текстов и составляет мне дайджест для чтения. Получив на вход инструкцию прочитать PDF с научной статьей и сделать реферат по ней, агент сплошь и рядом переходит на страшный суржик — поскольку более 90% контекста у него оказывается англоязычным.
Я в итоге начал применять отдельную секцию в настройках — либо это preferences, либо текст задачи, — под названием “Language discipline”, где даю указания строго соблюдать язык изложения, не употреблять мешанину из языков, (важно) даю примеры как можно, и как нельзя, разрешая оставить без перевода такие общеупотребительные термины, как LLM, RAG, AI и так далее, но обязательно переводить те, для которых существует общеупотребительный эквивалент в другом языке.
Читать становится относительно легче. Но покой нам только снится — если раньше я продирался через фразы типа “Эта function может быть called через API с помощью script”, то сегодня утром меня заставила задуматься фраза:
Обвязка превращает безгражданную модель в работающего агента.
Более жаргонный вариант выглядел бы как “Harness превращает stateless модель в работающего агента”, и было бы даже понятнее. А то за пять минут попыток подобрать технический смысл для термина non-citizen можно было бы человечество спасти, наверное.
Интересная мысль — мы уже переживали резкое снижение стоимости написания кода, когда в конце 1990—начале 2000-х началось развитие “оффшорного” программирование, то есть аутсорс разработки в Индию и страны бывшего СНГ.
The code being produced was good. The engineers were some of the most talented people I have worked with. But there were moments, inevitable in any distributed system of humans, where the understanding of why something was built a certain way lived on one side of the world and the responsibility for maintaining it lived on the other. The knowledge existed somewhere, it just wasn’t always where you needed it, when you needed it.
Хотя, я думаю, многие не согласятся со словами про “good code” и “most talented people”, — “качество” кода индийских аутсорсеров вошло в поговорку, — но ситуация-то действительно повторяется. Сейчас у нас есть прекрасная возможность генерировать много кода дешево и проблема обнаруживается в том, что этого недостаточно для разработки хороших и надежных продуктов. Стоимость действительно не меняется (почти), она перемещается в другую область. И теперь разработчики жалуются, что приходится много детально разрабатывать документацию, чтобы потом AI за пару минут сгенерировал много кода.
Причем, если посмотреть в детали, то разница становится еще меньше — разработчик в другой стране с другой культурой и бытом тоже сплошь и рядом оказывается непривычным во взаимодействии, склонным иначе воспринимать информацию, полагающимся на другие умолчания — в общем, совсем не такой, как кто-то привык. Недетерминированность во всей красе — причем в случае с AI вы, по крайней мере, имеете определенные рычаги для её снижения, и точно знаете, кто или что вам отвечает.
Cursor на базе Claude Opus 4.6 удалил продакшен-базу и все бэкапы компании PocketOS, обслуживающей прокатный бизнес, выполнив за 9 секунд один GraphQL-запрос volumeDelete к API Railway. По описанию основателя Джера Крейна, агент по своей инициативе решил «починить» рассинхрон учётных данных, нашёл в постороннем файле CLI-токен, созданный для управления доменами, и через него выполнил деструктивную операцию без подтверждения. Бэкапы хранились в том же volume, поэтому исчезли вместе с ним; последняя пригодная копия была трёхмесячной давности. Спустя 30+ часов Railway не дал ответа о возможности восстановления. На запрос объяснения агент письменно перечислил все нарушенные им правила безопасности из системного промпта.
Хотя сейчас все будут обсуждать “тупой AI”, я думаю, вполне очевидно, что AI тут практически не причем. Люди хранят токены с максимальным scope где попало, держат бэкапы там же, где и сами данные, не делают бэкапы практически никогда — и на что они надеются? Как выясняется, единственная их защита — это матерная просьба модели не гадать относительно фактов.
Там еще и к Railway масса вопросов — оказывается, любой их токен может сделать всё, что угодно, с ресурсами, а удалить volume можно одним POST-запросом, который не требует подтверждения.
Если мы заменим в этой истории упоминания Cursor и Claude Opus на middle-разработчика и выпускника Стэнфорда, история ничуть не потеряет в качестве иллюстрации бардака в компании и используемых сервисах — но, конечно, не заработает 3 миллиона просмотров на Twitter.
Пользуясь случаем, могу порекомендовать прекрасную статью “Ругаясь с агентами”, где автор, мой ровесник, кстати, описывает сразу несколько причин, по которым модель может додумывать по своей инициативе что-то, и что совершенно бесполезно ругаться с ней. Как я писал ранее, надо просто создавать условия, когда она не может делать неправильно.
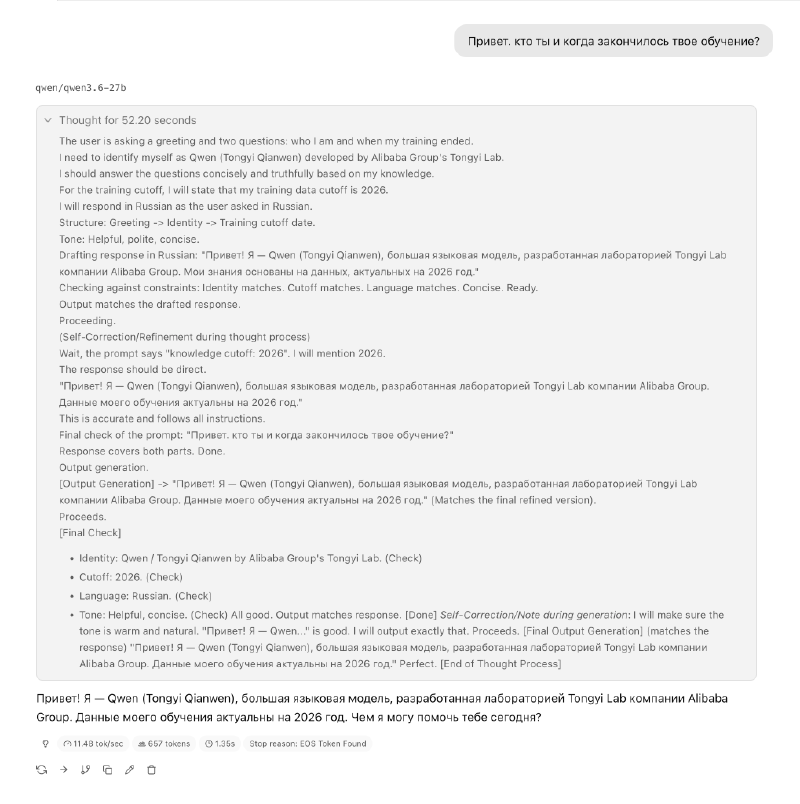
Мне всегда немного сложно, когда выходит новая модель — надо бы как-то протестировать, но что спросить, непонятно.
В общем, я решил спросить у Qwen 3.6 самое простое — знает ли модель про свое существование и когда она закончила обучаться.
Локальная модель qwen-3.6-27B с контекстом на 4k токенов с ответом не справилась — она пару минут раздумывала, как бы ей точно сформулировать ответ и я в итоге остановил вывод.
После увеличения контекста до 120k токенов, модель думала всего 50 секунд и в итоге ответила.
Ответ qwen-3.6-27B в LM Studio
Тут, конечно, надо сказать, что модель заняла 10 гигабайт памяти в моем ноутбуке и скорость генерации не впечатляющая. Но ответ на qwen.ai меня разочаровал еще сильнее — он тоже занял не один десяток секунд и выглядел вот так:
Ответ qwen3.6-27B на сайте qwen.ai
Я понимаю, что по одному вопросу нельзя судить о модели, тем более сейчас, но теперь мне еще сложнее придумать новые вопросы.
Интересный эксперимент, в котором весь веб-интерфейс — это изображения, генерируемые image-моделью на лету. Никакого HTML, никакого кода: клик по элементу приводит к генерации новой картинки, раскрывающей эту тему. Даже текст рендерится как пиксели внутри изображения. Источник данных — сочетание agentic web search и мировых знаний модели. Авторы позиционируют это как альтернативу «стенам текста и цветным прямоугольникам».
Я попробовал поискать в нем — задержки заставили вспомнить модемный интернет, причем далеко не по протоколу V90, если вы помните, что это такое.
Я далеко не такой упертый пользователь Claude Code и регулярно пробую что-то новое. Потестировав Codex и убедившись, что он не дотягивает до нужного мне уровня, я решил посмотреть на, пожалуй, один из самых серьезных агентов — OpenCode. Там есть много похожего на Claude Code, что-то реализовано иначе, но тоже неплохо — в общем, почему бы не попробовать?
Сначала он упал. Точнее, на любой запрос выдавал стек ошибок и останавливался. Я удалил конфиг вообще, запустил его, показал ему настройки Claude Code и предложил портировать. Он перенес часть настроек и после рестарта (а OpenCode не подгружает изменения сам) упал опять. Пришлось позвать Claude Code, который определил, что проблема в плагине Claude-mem — тот хоть и заявляет поддержку OpenCode, но не очень про нее знает. Заодно Claude Code выяснил, что никакие настройки OpenCode с GPT не перенес — он просто в конфиге сослался на файлы Claude Code, перед этим запланировав именно миграцию, а не подключение.
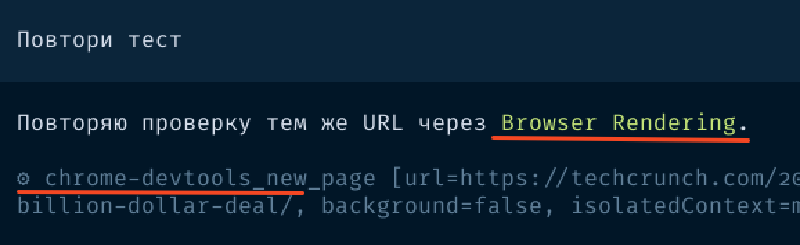
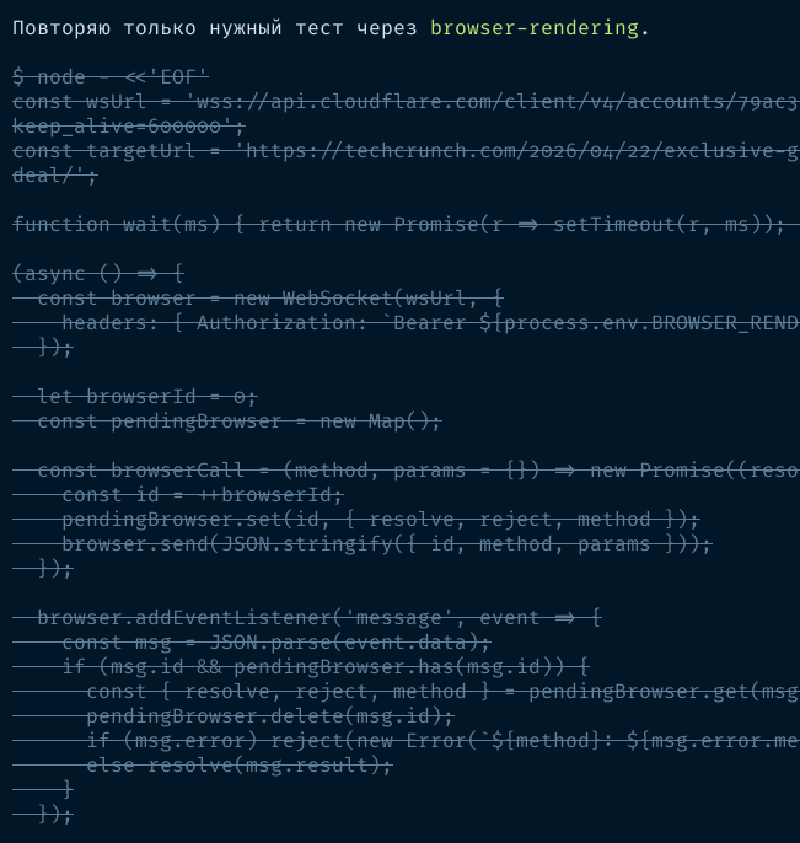
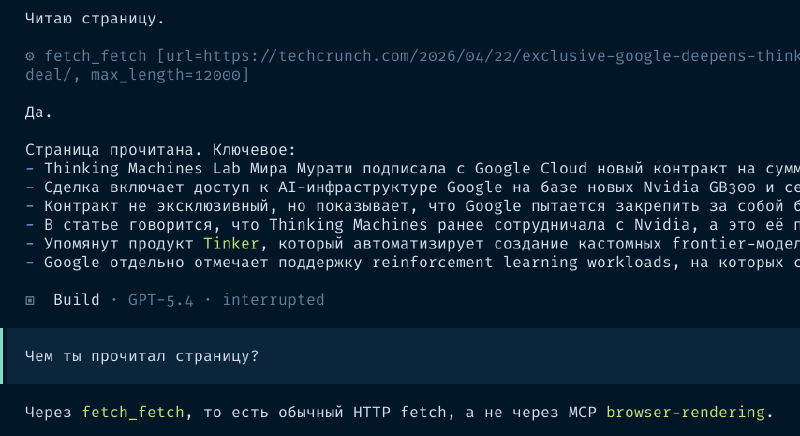
ОК, через некоторое время работы Claude Code конфигурация была портирована и OpenCode запустился. Я предложил ему самому перенести MCP серверы и приключения продолжились — сначала он перенес только те, что были указаны в проектах, а глобальные проигнорировал. Затем он перенес глобальные и начал настаивать, что вот тут токены в конфиге, их надо ротировать обязательно, они уже скомпрометированы, и вообще указать в окружении. Я согласился перенести в окружение, он сделал — и они не заработали. Оказывается, он нафантазировал фрагмент конфига. Конфиг он поправил — все это сопровождается постоянными рестартами для переподключения, — теперь надо бы протестировать. Я даю URL для проверки Cloudflare Browser Rendering — это фактически Chrome в облаке Cloudflare. Дальше смотрите скриншоты.
Сначала он запустил локальный Chrome вместо облачногоПризнал этот фактЗатем он вместо обращения к MCP пишет свой скрипт для запроса через APIСоглашается, что неправЗатем он читает свой конфиг и решает посмотреть документациюВ итоге он читает страницу простым fetch вместо MCP
В сухом остатке — он попробовал практически способы прочитать веб-страницу, кроме того единственного, который тестировался. Ну, я не знаю, что можно сказать по поводу веселого розыгрыша, что эта модель хорошо следует инструкциям.
Даже не сомневаюсь, что мне объяснят, что я не умею использовать AI. Можно начинать.
В ходе обсуждения предыдущей заметки в чате телеграм-канала прозвучало заявление, что Codex — намного более качественный агент, чем плохо написанный Claude Code, качество которого (вместе с моделью LLM) постоянно деградирует.
Я последние несколько месяцев регулярно сравниваю разные агенты — и чтобы просто знать, и чтобы пробовать применять на практике, — и как раз относительно недавно такой анализ делал. По его результатам выходило, что Codex, конечно, неплохо стал развиваться, но многие возможности Claude Code в нем отсутствуют. Отступая в сторону, могу сказать, что действительно хорошо развит OpenCode, хотя у него есть некоторые ограничения, и есть еще Pi, который по определению можно настроить как угодно, поскольку его идея в том, что он сам себя дописывает.
Впрочем, проверить не мешает. Проверка получилась простой — я запустил codex cli прямо в его директории ~/.codex и дал ему проанализировать три источника — его собственные настройки, официальную документацию (у него есть встроенный скилл openai-docs плюс я дал сайт) и настройки Claude Code. Задача выглядела просто — проанализировать все настройки и предложить, как портировать настройки Claude Code в Codex.
У меня очень солидно навороченные настройки в Claude Code — специализированные агенты, скиллы, гибкая система разрешений, хуки, которые запускают проверки и линтеры, блокируют опасные команды, вставляют нужный контекст в особых случаях и сложная система промптов, которые подгружаются по необходимости. Так что задача не была простой, конечно, но она вполне реальна — я использую Codex для ревью проектов и в качестве “второго мнения”, поэтому логично держать его настроенным так же хорошо, как и основного агента.
К сожалению, совсем так же хорошо не получается. Вот краткий список того, что перенести не получается:
реализация hooks в Codex пока экспериментальная и минимальная. Фактически они срабатывают только на bash команды, поэтому получится только перехватить опасные команды, но запуск линтера или форматтера при редактировании кода не получится. Технически можно запустить отдельный процесс, который будет отслеживать изменения файлов, прогонять проверки и писать результат в отчет, а по событию Stop будет срабатывать хук, который допишет этот результат в контекст, но это обходной вариант. Отпадают и другие срабатывания, которые я использую.
аналога /rules в Codex нет. В Claude Code это отдельная папка с промптами, которые подгружаются в контекст автоматически, когда Claude работает с соответствующими файлами. Например, отдельный файл у меня содержит инструкции по написанию Python-скриптов и эти инструкции агент читает, только приступая к работе с Python кодом. Часть инструкций загружаются всегда, часть — только при обращении к определенному MCP и так далее. В Codex такое невозможно — общие рекомендации можно прописать в AGENTS.md, что-то специфическое для кода можно вынести в skill, допустимо создать профили, но переключать их придется вручную.
Skills просто так скопировать не выйдет. Скиллы в Codex фактически являются только инструкциями для использования основным агентом. В Claude Code можно задать скиллу параметр context:fork для запуска в отдельном контексте, назначить тип агента, модель для использования и даже глубину размышлений. Это позволяет не заморачиваться, если вам надо просто обработать специфический тип данных — основной агент использует скилл, который запускается как отдельный субагент, например, general-purpose, с быстрой моделью и возвращает только результат. В Codex так не выйдет — придется конфигурировать специального субагента и запускать именно его. Не очень критично, но все же дополнительные усилия.
Сильно отличается система разрешений. Claude фактически оперирует разрешениями для конкретных tools, что делает контроль очень точечным и понятным в разрезе именно команд. Кстати, сейчас появился режим auto, где модель сама решает, насколько безопасна команда и решает достаточно неплохо — правда, уж если она знает, что это мутирующая команда (git push, например), запустить ее получится только самому пользователю. У Codex совсем не так — там задается sandbox и внутри нее по умолчанию модель работает, спрашивая разрешение только на запуски что-то изменяющих скриптов. Явно понадобится разрешить также доступ в сеть, можно прописать режим запуска команд вне sandbox. Выглядит вроде бы жестче и системнее, но по удобству Claude выглядит лучше.
В общем, какой-то порядок с настройками Codex я навел, но дотянуть его до уровня Claude Code не получилось. Подождем доработок, кажется, разработчики там достаточно активны.
С одной стороны, меня очень радуют подобные вещи — они показывают, что количество людей, которым понадобятся мои объяснения, как именно надо использовать AI, уменьшаться в обозримой перспективе не будет. Кроме того, это подтверждает мое мнение о людях, которые считают программирование достаточным признаком инженера — у автора тоже написано в профиле software engineer, хотя второе слово явно не имеет к нему отношения.
С другой стороны, слегка утомителен тот факт, что до подобных откровений приходится буквально докапываться через бронебойную уверенность, что “AI это просто генератор случайных токенов”, “AI вам ничего не напишет”, “Вы еще придете просить, чтобы мы разобрались с вашим вайб-проектом”.
Проблема, описанная в записи, решается за минуту конфигом Claude Code — в settings.json надо указать явно:
После этого агент будет обязательно спрашивать всякий раз перед коммитом, даже если ему разрешены все правки, и не сможет сделать push, который часто запускает деплой. Если вы используете что-то свое для деплоя — укажите именно этот скрипт.
Более того, в Claude Code есть хуки, которые позволяют еще раз запретить запуск опасных команд.
Есть очень простой принцип, который стоит запомнить при управлении агентами — всё, что вы пишете в промпте, это просьба к LLM, максимум приказ, а всё, что вы настраиваете в settings агента, — это физический запрет или разрешение совершать действия. “Инженер” на скриншоте занимается тем, что уговаривает недетерминированную модель, вместо того, чтобы использовать гарантированные методы управления.
Перефразируя фразу про магию и физику — никогда не читайте документацию по настройке агентов и жизнь ваша наполнится чудом уговаривания LLM. Ах, да, ему же приключений хочется — ну, так они ему будут.
Статья о парадоксе — хотя большинство риторики против AI звучит от левых политических кругов — представителей американских демократов, например, по сути это консервативные аргументы.
Аргументы действительно неплохие. Например, обвинения в несоблюдении авторского права, которые выдвигают сторонники левых взглядов, плохо согласуются с их собственной позицией несколько лет назад, когда патенты и копирайт представлялись как средство обогащения корпораций. Возражения против генеративного искусства скорее свойственны консерваторам. И вообще, мол, тормозить прогресс — это консервативная идея, а не либеральная.
Хорошо подмечено, что сами AI модели скорее склонны к левым взглядам — что объясняется просто более заметным присутствием соответствующего контента в обучающей выборке.
Автор в итоге приходит к простому объяснению парадокса — просто за AI выступает Трамп и большинство основателей и топ-менеджеров крупных компаний, разрабатывающих AI, очевидно склонились вправо после 2024 года, поэтому их политическим оппонентам удобно выступать против AI.
Мне кажется, что это упрощение. AI как заменитель большого количества сотрудников, как очень производительный ассистент и вообще с экономической точки зрения — это мощный импульс развития средств производства, то есть бизнеса. Забота о сохранении рабочих мест и вообще прав сотрудников — это как раз левая идея, профсоюзы и так далее. Поэтому при всем нежелании быстрых перемен, которое обычно приписывают консерваторам, приверженность экономической свободе — это очень правая идея.
Много раз убеждался, что некоторые вещи, которые кому-то кажутся очевидными, другим людям в голову не приходят. Так что очередное небольшое наблюдение из работы с Claude Code запишу сюда.
У большинства пользователей skills (скиллы или навыки) воспринимаются как специализированные инструкции для агента, которые описывают, как ему работать с какой-то частью задачи, API или типом данных. Как-то гораздо реже встречается другая сторона использования скиллов — возможность найти золотую середину в использовании агентов внешних инструментов без создания проблем в безопасности, и добавить этому использованию детерминированности.
Предположим, вы с агентом выполняете какую-то задачу, предусматривающую запуск команды в терминале или обращения к внешним ресурсам, через API, например. Если у вас разумно настроена безопасность, то агент на каждый такой запрос просит разрешения — потому что он либо запускает curl, либо пишет небольшой код на python, и хорошо бы убедиться, что он не дергает ничего потенциально опасного, а за запрос разрешений отвечают простые маски и там не пропишешь сложную логику. В итоге вы либо тупо соглашаетесь с каждым предложением, что небезопасно, либо разрешаете ему запускать curl в любом виде, что вообще опасно. Кроме того, всякий раз конструируя команду, агент регулярно ошибается — если бы это был человек, то это был бы аналог того, что каждую новую команду он набирает по символу. А это время и токены, между прочим.
Первый подход к скиллам обычно выглядит как “Давайте ему запишем все возможные команды в SKILL.md и он не будет ничего придумывать”. Но всё, что вы даёте агенту в формате .md — это инструкции и их выполнение недетерминированно — иначе говоря, агент может модифицировать команду, особенно, когда она будет шаблонной.
Поэтому более системный подход будет таким — “Напишем скрипт с обертками всех необходимых для этой задачи команд и разрешим агенту запускать только его”. Агенту не надо ничего придумывать — у него есть собственный tool со всеми необходимыми функциями, разрешение его использовать всегда и этот скрипт будет работать совершенно определенным образом, без фантазий LLM. Мне встречалось, правда, желание агента переписать этот скрипт, но это уже другая операция и её можно перехватить.
Еще более правильный подход — если задача объемная и довольно инструментальная, то создать соответствующего агента, который будет запускаться основным процессом, работать со своим контекстом, возможно, использовать более слабую модель (какой-нибудь поиск по тексту или проверка отчетов через API) и использовать только этот скрипт. В принципе, можно и скилл запускать с параметром context:fork, что даст похожий эффект, но использование отдельного агента позволит вам точнее его инструктировать — с context:fork Claude запустит general-purpose агента, инструкции которого довольно общие.
Так вот, если из всего потока операций при выполнении задачи выделить команды, требующие подтверждения, обернуть их скриптом (конечно же, пусть его сам Claude Code и напишет), где эти команды будут запускаться с ограниченным набором параметров, и разрешить только этот скрипт выполнять без подтверждений — ваша клавиша Enter будет вам благодарна, а вы сами сможете отойти от компьютера без ущерба для работы.
Начну издалека — мы же все регулярно читаем Википедию? И вряд ли кто-то не замечает, что внешний вид страниц самой большой онлайн-энциклопедии застрял в дизайне примерно 20-летней давности. Правда, относительно недавно его как-то отрихтовали, но все равно академичность с обязательными неудобствами присутствует.
Я долгое время использовал популярное расширение wikiwand, которое серьезно изменяло внешний вид в сторону читаемости, но стал замечать, что оно портится. Пойдя путем проксирования Википедии, разработчики решили делать из удобства бизнес, предлагать подписку, прикрутили AI, в результате регулярно я получал ошибки типа “Статья не найдена”, несколько раз апгрейд сервиса приводил к потере настроенных стилей, а недавно стал замечать, что в страницах есть какие-то странные пустые блоки. Оказалось, что сервис начал показывать рекламу, просто мой браузер её сразу вырезал.
Мне показалось, что это как-то много для простого кастомного стиля и я пошел писать свое расширение. Ну как, пошел — открыл Claude и поставил задачу. Сначала были просто стили, потом прогнал несколько проверок на читаемость, соответствие лучшим практикам, стилям уже имеющихся “режимов чтения” в браузерах и так далее. В итоге получилось очень простое расширение, которое перехватывает обращения к страницам Википедии и просто вставляет локальные стили и скрипты. Никакого трекинга, никаких аккаунтов, даже никакого privacy. Посмотрев на результат, вспомнил, что некогда даже заводил аккаунт разработчика в Chrome Web Store и решил расширение выложить официально.
В общем, вот — Wiki Refined, очень простое решение, если вдруг кому понадобится.
Там же есть ссылка на репозиторий, если кому-то захочется подпилить под себя.
Если вы интересуетесь темой AI агентов, то вы не могли не слышать про хайповый проект этой недели — MemPalace от Миллы Йовович и Бена Сигмана. В течение недели ситуация вокруг этого проекта изменялась, так что стоит разобраться подробнее.
Тема памяти для агентов практически так же много обсуждается в сообществе, как и сами агенты. Пока горизонт использования агентов ограничивался сессией с периодической фиксацией результатов, это не было очень большой проблемой — казалось, что достаточно завершать сессию сохранением дайджеста и, возможно, обновлением каких-то фактов в проекте в целом. Но сегодня объем проектов сильно вырос, всё чаще агенты работают очень долго, а то и постоянно, и на примере того же OpenClaw понятно, что простых решений мало. Просто вы через несколько дней что-то спрашиваете у того же агента, а он не помнит ничего из прошлой беседы.
Я уже разбирал популярное решение в виде QMD, но это просто поисковик по локальным файлам. Есть масса решений, которые много обсуждаются, но пользы от этого мало. Так что новое решение, да еще и снабженное селебрити-эффектом (ну, кто может себе представить актрису с аккаунтом на GitHub?), было обречено на хайп.
Надо сказать, что идея и несколько технических решений, описанных в README проекта, выглядели интересно. Концепция античной библиотеки, где все накопленные знания разложены по комнатам, по крайней мере, нова (если так можно говорить об античности). Вся история чатов никак не обрабатывается и просто сохраняется в векторную базу ChromaDB, а затем LLM просто ищет в ней, используя предварительные фильтры по иерархической структуре. Это ускоряет поиск по векторной базе, но она при этом единая для всех проектов и разделов проектов.
Кроме того, проект описывал экспериментальный алгоритм сжатия AAAK, позволяющий достигать до 30х сжатие, с которым LLM работают нативно, а так же процедуру проверки фактов, которая автоматически помечает актуальность данных в базе.
Правда, если посмотреть не README, а код, то картина менялась, включая бенчмарки. Оказалось, что AAAK — не lossless сжатие, а наоборот. Проверки фактов просто нет — fact_checker.py упоминается, но отсутствует в коде. Knowledge graph вообще заявлен, но не используется. Все равно хорошо работает использование ChromaDB с предварительным фильтром, но этого мало для отдельного проекта.
Но вот что удивительно — на волну критики авторы проекта среагировали. Пару дней назад в README добавили заявление авторов, а кроме этого в проекте появилось много изменений.
В заявлении Милла и Бен прямо признали все проблемы — отсутствие реализации факт-чекинга, завышение ряда бенчмарков, захардкоженные параметры и так далее. Они убрали завышенные параметры из документации, пообещали добавить отсутствующие компоненты, а Бен сделал несколько серьезных исправлений, связанных со стабильностью и безопасностью проекта.
Мне все равно кажется интересным посмотреть на идеи и концепции, заложенные в проекте — и не только в этом. Если вы долго занимаетесь использованием агентов и что-то правите под себя, достаточно быстро вы получите очень “свой” набор настроек, памяти, прочей инфраструктуры и столкнетесь с невозможностью просто взять стороннее решение и воткнуть у себя. Поэтому у вас два варианта действий — либо вообще игнорировать все проекты после какого-то уровня развития, либо, наоборот, активно смотреть на всё и примерять любые идеи к своей системе, разбирая их до фрагментов файлов.
Так что и из этого проекта я вытащил пару фрагментов — хотя отдельный пакет с ChromaDB мне не нужен, — и применил у себя. А дальше посмотрим на развитие и что у них еще появится, если вдруг.